I have a table of job numbers, which are sequential based on entry time. Each Job has one or more product numbers. I'm looking for a way to find the three most recent jobs (highest job number) that contain each product number.
Get the list of jobs in reverse JobID order for each productID. Pick the first three.
I suggest using a script to set a field instead of using a calculation field. The calculation field would be unstored and slow. Set this value for the product when a product is added to a job.
Right. Since posting this, I'm thinking a nightly/weekend script that goes through and find all of the most recent jobs with the right part numbers, marking them for archive, then deleting/copying/whatever we decide to so with them.
I was trying to do with with a calulated field at first, but you're right - too slow.
I think that's the biggest hurdle coming to FileMaker from Oracle - I miss pre-compiled Oracle views where you could do that sort of thing a little easier.
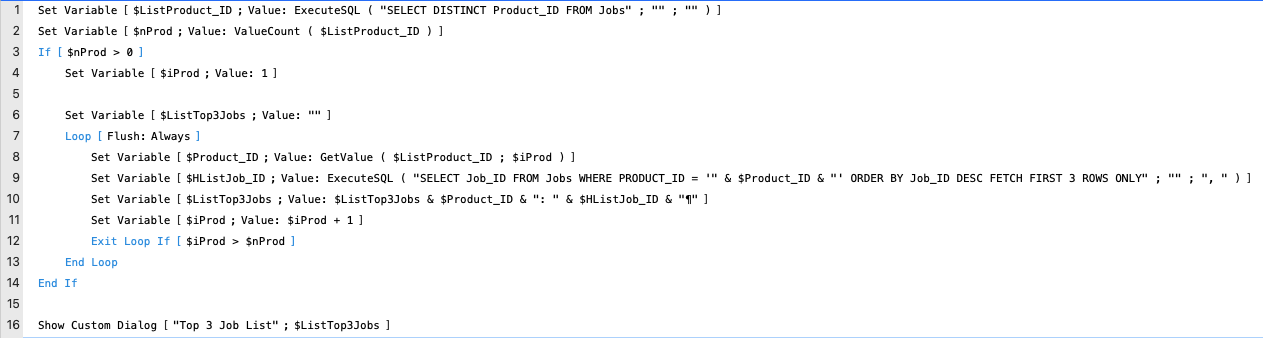
I’d recommend using a script using ExecuteSQL similar to this recommended here by @LucThomaere.
Do everything you can to avoid sorted relationships, they are very bad as far as performance goes. It is always worth remembering that just because you can do something within FileMaker doesn’t necessarily mean you should do it that way.
very hard to debug (though there is a new function ExecuteSQLe which returns better error messages ExecuteSQLe )
field names are hard-coded, and won't update if you rename a field (you can work around this by using GetFieldName() but the syntax is somewhat ugly)
performance may or may not be better - I've seen it go both directions.
Also, Luc's code as written is vulnerable to a SQL Injection attack. Much safer to use parametrized arguments
That being said, my decision which way to do it would depend...
is this a one-off calculation that is rarely used and we don't want to clutter the schema with new relationships or fields? Perhaps use SQL.
is this a core feature of the database, so that the relationships and calculated fields are actually useful (as they tend to be somewhat self-documenting, and open to inspection for debugging). Use relationships and calculated fields.
@xochi another factor that I don’t think has been defined here, is whether this is hosted on a local network and accessed by local computers, or is accessed remotely, or hosted on the cloud.
If accessed via the Internet, the design of any system should be optimised for this. Hence, long chains of table occurrences, tables with many fields, etc. will have a significant impact on performance.
The performance of ExecuteSQL is likewise impacted by the design. Never use it in ‘Set Field’ (or ‘Replace Field Contents)’, always have the record in a committed state before setting a variable, and avoid JOIN where possible. There are well documented techniques on the web, such as using ‘IN’ and running 2 eSQL functions, rather than a single function using ‘JOIN’s.
As you’ve mentioned, nobody should be hard coding table or field names, wrapping these in some simple custom functions ensures robust coding and using a Let allows the SQL syntax to be viewed before executing.
Having been designing FileMaker systems for delivery via the Internet for 12-years, we now avoid calculation fields, particularly cross table calculation fields. All the business logic is scripted, which ensures the structure remains as simple as possible so that the data processors have the fastest speed. The delivery of ‘heavyweight’ reports, validation, and complex calculations is only carried out via scripts when they are needed.
A lot of FileMaker’s features are retained for backwards compatibility, which is great. However, many of these should not be used going forward. Yes, much of what I’m suggesting takes a lot more time than the obvious solution. Equally, there are many FileMaker systems discarded due to them running slowly due to the design being for LAN use and the transition to WAN not being successful.
Again, this may be a holdover from my Oracle days, but what you're suggesting is to not normalize your database the way one might in other systems. Store values in multiple places rather than relying on queries to grab them from the single place they're stored.
That would not be the right thing to take away from the discussion.
TLDR; Denormalising data for the advantage of performance, delivery, etc, is OK. On the other hand, you'll find that taking DB design to 3NF in FileMaker is typical.
You have to start by discussing your use case. FileMaker, unlike most databases, has always had the capacity to run on the desktop. This means that there is a very large base of users who do not use FileMaker in a client/server situation and have absolutely no need to consider bandwidth, latency, or server config. These users can, and often do, design systems without any need to consider resource use, delivery methods, performance bottlenecks, etc. Additionally, individual users don't generate a lot of data by themselves. You need teams, or large client groups to do that.
Sometimes those systems become business critical, and grow, and get put into a server/client situation, and then that gets moved to offsite infrastructure, or staff try to access the systems from home, or on the move, or offer a front-end to clients. That's when we start to hear people complaining, because they are using a system that is designed as a rollercoaster, and they expect it to seamlessly transition into a freeway system.
As you're coming from an environment where the rules are much stricter, I'd suggest that you behave as normal when designing the backend. Enjoy using the interface tools that make FileMaker so simple.
One thing I like about FileMaker is that it's very easy to define calculations within a Table by using calculated Fields.
In addition to the great points that @Malcolm raises...
However, there's some hidden complexity with calculated fields that can cause confusion:
An unstored calculated field is conceptually more like a SQL View - it's real in the sense that you can use the values, but it doesn't really exist (no data is stored in the table). So you aren't really denormalizing. These fields are limited (can't be indexed, and can't be on the To side of a From X To Y relationship).
A stored calculated field actually exists, and can be indexed, and thus might be a way to intentionally denormalize your data (to trade off size vs. performance). However, stored calculated fields can only use data from within a single table, which limits their utility.
A problem that I run into with calculated fields is that there's no easy way to group them. I have situations where I need a dozen calculated fields for one report, and a different dozen for another report (etc.). Other than using clever naming conventions, there's no easy way to group and hide these fields.
What I'm hearing is I need to learn to be more open-minded and less rigid about normalization in the design of my databases with Filemaker than in more Enterprise-designed solutions.
I gotta be honest - I miss SQL views. Each screen would have an SQL view, easy peasy.
I'm also hearing that I'm using far too many unstored calculations, especially that use ExecuteSQL.
Thanks very much to everyone for an enlightening discussion. I've learned a lot just from this.